When you use VeryPDF OCR to Any Converter, you will find that the default OCR language of the program is English and it can only recognize English characters in image or scanned document. But if you have some file which contains French, Chinese, Bulgarian, etc., how to use OCR to Any Converter to recognize these characters?
Of course, there must be the related language packages in the program at first and then you need to choose the language you need in the conversion to OCR the characters. OCR to Any Converter allows you to download different kinds of OCR language packs to the program and then you can use the program to recognize different languages.
To download OCR to Any Converter, please click here.
When you open the application by double clicking its icon or launching it through Start menu, you can see the main interface of OCR to Any Converter. For example, if you want to recognize Czech characters and there is no this kind of language packs in the program, please do as follows:
1. Click Settings—Download Language Data like the operations in Figure 1 to open the window for downloading Czech language.
Figure 1
2. In the popup window like the one shown in Figure 2, please choose Czech with your mouse and click Download button until the downloading work is over. Then click Close button.
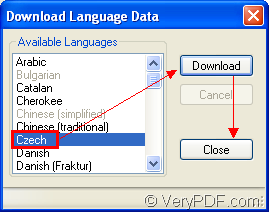
Figure 2
3. The popup window will remind you to restart the program to register the downloaded language, please see it in Figure 3. After clicking on OK button, please close OCR to Any Converter and restart it again.
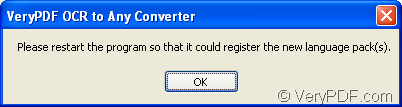
Figure 3
4. When you open OCR to Any Converter again, please click OCR Language dropdown list and you will find the downloaded Czech language has been successfully loaded. Please see it in Figure 4.
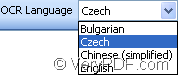
Figure 4
Then you can use OCR to Any Converter to recognize Czech characters at once. With the same way, you can also download other OCR language packs, too.
If you have any other questions about OCR to Any Converter, please contact our support team.