PDF to Text OCR Converter Command Line v3.5 can be downloaded and purchased from following web page,
https://www.verypdf.com/app/pdf-to-text-ocr-converter/index.html
VeryPDF has released PDF to Text OCR Converter Command Line v3.5 today, the new version has following new features,
1. Able to download OCR Language Package from VeryPDF site automatically,
Supported OCR Languages:
https://www.verypdf.com/pdf2txt/ocr-language.htm
You can use "-lang" parameter to specify language for OCR engine, e.g.,
pdf2txtocr.exe -ocr -res 300 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -lang eng C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -lang eng -ocrmode 0 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -lang eng -ocrmode 0 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -lang deu -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 2 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 3 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 2 -outboxfile C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang fra -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang ita -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang nld -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang spa -ocrmode 1 C:\in.pdf C:\out.pdf
"-lang" option can be choose from one of following OCR languages, if a language package
is not exist in OCR Data Folder, pdf2txtocr.exe will download necessary language package
from VeryPDF site automatically.
bul: Bulgarian language
cat: Catalan language
ces: Czech language
chi_sim: Chinese (Simplified) language
chi_tra: Chinese (Traditional) language
chr: Cherokee language
dan: Danish language
deu: German language
ell: Greek language
eng: English language
fin: Finish language
fra: French language
hun: Hungarian language
ind: Indonesian language
ita: Italian language
jpn: Japanese language
kor: Korean language language
lav: Latvian language
lit: Lithuanian language
nld: Dutch language
nor: Norwegian language
pol: Polish language
por: Portuguese language
ron: Romanian language
rus: Russian language
slk: Slovak language
slv: Slovenian language
spa: Spanish language
srp: Serbian language
swe: Swedish language
tgl: Tagalog language
tur: Turkish language
ukr: Ukranian language
vie: Vietnamese language
For example, you can run following command line to convert Japanese Characters from scanned PDF file to text file,
pdf2txtocr.exe -ocr -lang jpn D:\downloads\Japanese.pdf D:\downloads\Japanese.txt
This is original PDF file which contains scanned Japanese characters,

This is the OCRed text contents, the Japanese Characters are look fine,

The following are full command line options included in the new version of PDF to Text OCR Converter Command Line application,
C:\>pdf2txtocr.exe
VeryPDF PDF to Text OCR Converter Command Line v3.5
Web: https://www.verypdf.com
Web: http://www.verydoc.com
Email: support@verypdf.com
Release Date: Nov 27 2013
-------------------------------------------------------
Description:
1. Convert text based PDF files to plain text files.
2. Convert scanned PDF files and image files to plain text files and searchable PDF files by OCR technology.
3. Convert embedded fonts in PDF file to a new searchable PDF file.
4. Keep color during PDF, TIFF and image formats to searchable PDF files conversion.
5. Deskew, Despeckle and Noise Removal, Auto-Orientation, Dithering, Black Border Removal.
Input formats:
1. Text based PDF files
2. Scanned PDF files
3. Scanned single page and multi-page TIFF files
4. Scanned JPEG, PNG, BMP, GIF, PCX, TGA, PBM, PNM, PPM files
Output formats:
1. Plain text files without layout
2. Plain text files with layout
3. Plain text based PDF files (PDF is contain text only)
4. Attach OCRed text layer to original PDF file
5. OCRed BW PDF files with hidden text layer
6. OCRed Color PDF files with hidden text layer
7. OCRed Grayscale PDF files with hidden text layer
8. Output to TIFF, PNG, BMP, TGA, GIF with Deskew, Despeckle, etc. options
-------------------------------------------------------
Usage: pdf2txtocr.exe [options] <PDF-file> <Text-file>
-firstpage <int> : first PDF page to convert
-lastpage <int> : last PDF page to convert
-res <int> : set resolution, the unit is DPI (default is 300 dpi)
-ownerpwd <string> : set owner password for encrypted PDF file
-userpwd <string> : set user password for encrypted PDF file
-layout : maintain original physical layout
-noc : don't insert page breaks 0x0C between pages in text file
-bitcount <int> : set color depth when render PDF page to image data, it can be set 1, 8, 24, default is 8bit
-rotate <int> : rotate pages before OCR
-threshold <int> : lightness threshold that used to convert image to B&W, from 1 to 255, 0 is auto, default is -1
-imageopt : deskew and despeckle images automatically
-dither <int> : convert the color image to B&W using the desired method:
-dither 0: Floyd-Steinberg
-dither 1: Ordered-Dithering (4x4)
-dither 2: Burkes
-dither 3: Stucki
-dither 4: Jarvis-Judice-Ninke
-dither 5: Sierra
-dither 6: Stevenson-Arce
-dither 7: Bayer (4x4 ordered dithering)
-resizewidth <int> : resize the image's width, only availalbe when -resizeheight used
-resizeheight <int> : resize the image's height, only availalbe when -resizewidth used
-flip : flip the image vertically
-mirror : mirror the image horizontally
-ocr : enable OCR function for scanned PDF file
-lang <string> : choose the language for OCR engine
-ocrmode <int> : set OCR mode
-ocrmode 0: output to text file
-ocrmode 1: OCR PDF pages and insert new text layer under original PDF pages
-ocrmode 2: output to plain text based PDF file
-ocrmode 3: output to OCRed PDF file (BW) with hidden text layer
-ocrmode 4: output to OCRed PDF file (Color) with hidden text layer
-text <string> : add additional text at end of each text page, this parameter supports the following variables:
%PageNumber%: current page number
%PageCount% : total page count of PDF file
-outboxfile : output [X, Y, Width, Height] information for each word when OCR
-producer <string> : Set 'producer' to output PDF file
-creator <string> : Set 'creator' to output PDF file
-subject <string> : Set 'subject' to output PDF file
-title <string> : Set 'title' to output PDF file
-author <string> : Set 'author' to output PDF file
-keywords <string> : Set 'keywords' to output PDF file
-ownerpwdout <string> : Set 'owner password' to output PDF file
-openpwdout <string> : Set 'open password' to output PDF file
-keylen <int> : Key length (40 or 128 bit)
-keylen 0: 40 bit RC4 encryption (Acrobat 3 or higher)
-keylen 1: 128 bit RC4 encryption (Acrobat 5 or higher)
-keylen 2: 128 bit RC4 encryption (Acrobat 6 or higher)
-encryption <int> : Restrictions
-encryption 0: Encrypt the file only
-encryption 3900: Deny anything
-encryption 4: Deny printing
-encryption 8: Deny modification of contents
-encryption 16: Deny copying of contents
-encryption 32: No commenting
===128 bit encryption only -> ignored if 40 bit encryption is used
-encryption 256: Deny FillInFormFields
-encryption 512: Deny ExtractObj
-encryption 1024: Deny Assemble
-encryption 2048: Disable high res. printing
-encryption 4096: Do not encrypt metadata
-$ <string> : input your License Key
Examples:
pdf2txtocr.exe C:\in.pdf C:\out.txt
pdf2txtocr.exe -firstpage 1 -lastpage 1 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -res 300 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ownerpwd 123 -userpwd 456 C:\in.pdf C:\out.txt
pdf2txtocr.exe -layout C:\in.pdf C:\out.txt
pdf2txtocr.exe -noc C:\in.pdf C:\out.txt
pdf2txtocr.exe C:\in.tif C:\out.txt
pdf2txtocr.exe C:\in.jpg C:\out.txt
pdf2txtocr.exe C:\in.bmp C:\out.txt
pdf2txtocr.exe C:\in.png C:\out.txt
pdf2txtocr.exe -ocr -lang eng C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -bitcount 1 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -bitcount 8 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -bitcount 24 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -lang deu C:\in.pdf C:\out.txt
pdf2txtocr.exe -lang deu C:\in.tif C:\out.txt
pdf2txtocr.exe -text "PageText %PageNumber% of %PageCount%" C:\in.pdf C:\out.txt
pdf2txtocr.exe -subject "subject" C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ownerpwdout 123 -keylen 2 -encryption 3900 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -subject "subject" -title "title" C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 0 C:\in.pdf C:\out.txt
pdf2txtocr.exe -ocr -lang deu -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 2 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 3 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang eng -ocrmode 2 -outboxfile C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang fra -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang ita -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang nld -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocr -lang spa -ocrmode 1 C:\in.pdf C:\out.pdf
pdf2txtocr.exe -bitcount 24 -ocrmode 4 -ocr C:\in.pdf C:\out.pdf
pdf2txtocr.exe -bitcount 8 -ocrmode 4 -ocr C:\in.pdf C:\out.pdf
pdf2txtocr.exe -ocrmode 4 -ocr C:\in.tif C:\out.pdf
pdf2txtocr.exe -ocrmode 3 -threshold 200 -ocr C:\in.tif C:\out.pdf
pdf2txtocr.exe -ocrmode 4 -rotate 90 -ocr C:\in.tif C:\out.pdf
Process image files with Deskew, Despeckle and Noise Removal, Black Border Remova options:
pdf2txtocr.exe -imageopt C:\in.tif C:\out.tif
pdf2txtocr.exe -imageopt -rotate 45 C:\in.png C:\out.tif
pdf2txtocr.exe -imageopt -rotate 90 C:\in.png C:\out.tif
pdf2txtocr.exe -imageopt -threshold 0 C:\in.tif C:\out.bmp
pdf2txtocr.exe -threshold 240 C:\in.tif C:\out.bmp
pdf2txtocr.exe -dither 0 C:\in.bmp C:\out.png
pdf2txtocr.exe -dither 7 C:\in.bmp C:\out.png
pdf2txtocr.exe -imageopt -resizewidth 800 -resizeheight 600 C:\in.gif C:\out.tga
pdf2txtocr.exe -imageopt -flip C:\in.png C:\out.gif
pdf2txtocr.exe -imageopt -mirror C:\in.tif C:\out.pcx
pdf2txtocr.exe -imageopt C:\in.bmp C:\out.tif
Following command line will OCR all PDF files in D:\temp\ folder to text files:
for %F in (D:\temp\*.pdf) do pdf2txtocr.exe -ocr -lang deu "%F" "%~dpnF.txt"
Following command line will OCR all PDF files in D:\temp\ folder and subdirectories to text files:
for /r D:\temp %F in (*.pdf) do pdf2txtocr.exe -ocr "%F" "%~dpnF.txt"
Following command line will OCR all PDF files from D:\temp\ folder and output text files to C:\test folder:
for %F in (D:\temp\*.pdf) do pdf2txtocr.exe -ocr "%F" "C:\test\%~nF.txt"
The following are some command line examples in the new version of PDF to Text OCR Converter Command Line application,
pdf2txtocr.exe -ocrmode 4 test_color.tif _test\_test_color.pdf pdf2txtocr.exe -ocr -ocrmode 4 -res 72 _test\_test_color.pdf _test\_test-pdf2pdf-grayscale.pdf pdf2txtocr.exe -ocr -ocrmode 4 -res 72 -bitcount 24 _test\_test_color.pdf _test\_test-pdf2pdf-color.pdf pdf2txtocr.exe -imageopt -ocr -ocrmode 3 test_skew.tif _test\_test_skew.tif.pdf pdf2txtocr.exe test_multi_columns.pdf _test\_test_multi_columns.pdf.txt pdf2txtocr.exe test_multi_columns.tif _test\_test_multi_columns.tif.txt pdf2txtocr.exe -layout test_multi_columns.pdf _test\_test_multi_columns.pdf.layout.txt pdf2txtocr.exe -ocr -ocrmode 1 test_multi_columns.pdf _test\_test_multi_columns_mode1.pdf pdf2txtocr.exe -ocr -ocrmode 2 test_multi_columns.pdf _test\_test_multi_columns_mode2.pdf pdf2txtocr.exe -ocr -ocrmode 3 test_multi_columns.pdf _test\_test_multi_columns_mode3.pdf pdf2txtocr.exe -ocr -ocrmode 3 -ownerpwdout 123 -keylen 2 -encryption 3900 test_multi_columns.pdf _test\_test_multi_columns_mode3_encryption.pdf pdf2txtocr.exe -ocr -outboxfile test_multi_columns.pdf _test\_test_outboxfile.txt pdf2txtocr.exe -text "======================== This is the page %PageNumber% of %PageCount% ========================" test_text.pdf _test\_test_text.pdf.txt pdf2txtocr.exe -layout -text "======================== This is the page %PageNumber% of %PageCount% ========================" test_text.pdf _test\_test_text.pdf.layout.txt pdf2txtocr.exe -bitcount 1 test_color.tif _test\_test_color.tif.bitcount1.tif pdf2txtocr.exe -rotate 45 test_color.tif _test\_test_color.tif.rotate45.tif pdf2txtocr.exe -threshold 240 test_color.tif _test\_test_color.tif.threshold240.tif pdf2txtocr.exe -threshold 0 test_color.tif _test\_test_color.tif.threshold.auto.tif pdf2txtocr.exe -dither 0 test_color.tif _test\_test_color.tif.dither0.tif pdf2txtocr.exe -dither 7 -resizewidth 200 -resizeheight 200 test_color.tif _test\_test_color.tif.dither7.resizewidth200.resizeheight200.tif pdf2txtocr.exe -imageopt test_despeckle.tif _test\_test_despeckle.tif pdf2txtocr.exe -imageopt test_skew.tif _test\_test_skew.tif pdf2txtocr.exe -flip -mirror test_color.tif _test\_test_color.tif.flip.mirror.tif pdf2txtocr.exe -bitcount 1 test_color_small.tif _test\_test_color_small.png.bitcount1.png pdf2txtocr.exe -rotate 45 test_color_small.tif _test\_test_color_small.png.rotate45.png pdf2txtocr.exe -threshold 240 test_color_small.tif _test\_test_color_small.png.threshold240.png pdf2txtocr.exe -threshold 0 test_color_small.tif _test\_test_color_small.png.threshold.auto.png pdf2txtocr.exe -dither 0 test_color_small.tif _test\_test_color_small.png.dither0.png pdf2txtocr.exe -dither 7 -resizewidth 200 -resizeheight 200 test_color_small.tif _test\_test_color_small.png.dither7.resizewidth200.resizeheight200.png pdf2txtocr.exe -threshold 0 test_color_small.tif _test\_test_color_small_imageopt.png pdf2txtocr.exe -imageopt _test\_test_color_small_imageopt.png _test\_test_color_small_imageopt2.png pdf2txtocr.exe -flip -mirror test_color_small.tif _test\_test_color_small.png.flip.mirror.png pdf2txtocr.exe -ocr -lang deu test_german.tif _test\_test_german.tif.txt pdf2txtocr.exe test_german.pdf _test\_test_german.pdf.txt
2. Support image Deskew, Despeckle and Noise Removal options,
-imageopt : deskew and despeckle images automatically
Process image files with Deskew, Despeckle and Noise Removal, Black Border Remova options:
pdf2txtocr.exe -imageopt C:\in.tif C:\out.tif
pdf2txtocr.exe -imageopt -rotate 45 C:\in.png C:\out.tif
pdf2txtocr.exe -imageopt -rotate 90 C:\in.png C:\out.tif
pdf2txtocr.exe -imageopt -threshold 0 C:\in.tif C:\out.bmp
pdf2txtocr.exe -threshold 240 C:\in.tif C:\out.bmp
pdf2txtocr.exe -dither 0 C:\in.bmp C:\out.png
pdf2txtocr.exe -dither 7 C:\in.bmp C:\out.png
pdf2txtocr.exe -imageopt -resizewidth 800 -resizeheight 600 C:\in.gif C:\out.tga
pdf2txtocr.exe -imageopt -flip C:\in.png C:\out.gif
pdf2txtocr.exe -imageopt -mirror C:\in.tif C:\out.pcx
pdf2txtocr.exe -imageopt C:\in.bmp C:\out.tif
Despeckle Example #1:
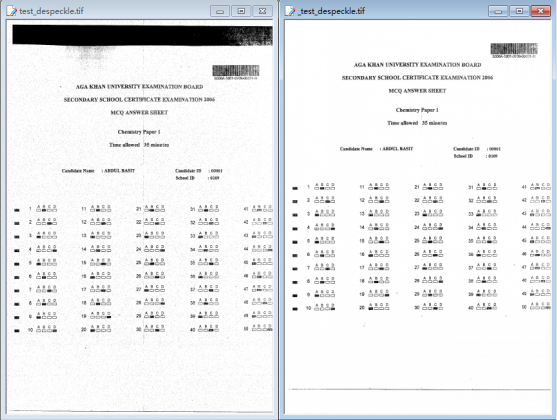
Despeckle Example #2:

![]()
Despeckle Example #3:

Deskewing:

PDF to Text OCR Converter Command Line v3.5 can be downloaded and purchased from following web page,
https://www.verypdf.com/app/pdf-to-text-ocr-converter/index.html