Compressing your PDF files
Compression and PDF
Compression is the reduction in size of data in order to save space or transmission time. For data transmission, compression can be performed on just the data content or on the entire transmission unit depending on a number of factors.Content compression can be as simple as removing all extra space characters, inserting a single repeat character to indicate a string of repeated characters, and substituting smaller bit strings for frequently occurring characters. This kind of compression can reduce a text file to 50% of its original size. Compression is performed by a program that uses a formula or algorithm to determine how to compress or decompress data. The algorithm is one of the critical factors to determine the compression quality.
To PDF files, compression refers to image compressing. PDF formats are usually designed to compress information as much as possible (since these can tend to become very large files). Compression can be either lossy (some information is permanently lost) or lossless (all information can be restored).
PDF is a page description language, like PostScript but simplified with restricted functionality to be more lightweight, which dues to not only a better data structure but also very efficient compression algorithms to reduce the file size to about half the size of an equivalent PostScript file. PDFs use the following compression algorithms:
All of these compression filters produce binary data, which can be further converted to ASCII base-85 encoding if a 7-bit ASCII representation is required.
The above algorithms can be divided into two distinct categories: lossless or lossy.
Lossless algorithms do not change the content of a file. If you compress a file and then decompress it, it has not changed. The following algorithms are lossless:
Lossy algorithms achieve better compression ratio's by selectively getting rid of some of the information in the file. Such algorithms can be used for images or sound files but not for text or program data. The following algorithms are lossy:
It is in how well you use these compression techniques, how efficiently the data is described, and the complexity of the document (read number of fonts, forms, images, and multimedia) that ultimately determines how large your resulting PDF file will be.
Compression algorithm introduction
The compression algorithms can be described in detail below.
ZIP works well on images with large areas of single colors or repeating patterns, such as screen shots and simple images created with paint programs, and for black-and-white images that contain repeating patterns. Acrobat provides 4-bit and 8-bit ZIP compression options. If you use 4-bit ZIP compression with 4-bit images, or 8-bit ZIP with 4-bit or 8-bit images, the ZIP method is lossless, which means it does not remove data to reduce file size and so does not affect an image's quality. However, using 4-bit ZIP compression with 8-bit data can affect the quality, since data is lost.
Note: Adobe implementation of the ZIP filter is derived from the zlib package of Jean-loup Gailly and Mark Adler, whose generous assistance we gratefully acknowledge.
(International Coordinating Committee for Telephony and Telegraphy) is appropriate for black-and-white images made by paint programs and any images scanned with an image depth of 1 bit. CCITT is a lossless method. Acrobat provides the CCITT Group 3 and Group 4 compression options. CCITT Group 4 is a general-purpose method that produces good compression for most types of monochrome images. CCITT Group 3, used by most fax machines, compresses monochrome images one row at a time.
RLE (Run Length Encoding) is a lossless compression option that produces the best results for images that contain large areas of solid white or black.
JPEG stands for Joint Photographic Experts Group, which is a standardization committee. It also stands for the compression algorithm that was invented by this committee.
There are two JPEG compression algorithms: the oldest one is simply referred to as "JPEG" within this page. The newer is JPEG 2000 algorithm
JPEG is a lossy compression algorithm that has been conceived to reduce the file size of natural, photographic-like true-color images as much as possible without affecting the quality of the image as experienced by the human sensory engine. We perceive small changes in brightness more readily than we do small changes in color. It is this aspect of our perception that JPEG compression exploits in an effort to reduce the file size
JPEG is suitable for grayscale or color images, such as continuous-tone photographs that contain more detail than can be reproduced on-screen or in print. JPEG is lossy, which means that it removes image data and may reduce image quality, but it attempts to reduce file size with the minimum loss of information. Because JPEG eliminates data, it can achieve much smaller file sizes than ZIP compression.
Acrobat provides six JPEG options, ranging from Maximum quality (the least compression and the smallest loss of data) to Minimum quality (the most compression and the greatest loss of data). The loss of detail that results from the Maximum and High quality settings is so slight that most people cannot tell an image has been compressed. At Minimum and Low, however, the image may become blocky and acquire a mosaic look. The Medium quality setting usually strikes the best balance in creating a compact file while still maintaining enough information to produce high-quality images.
JBIG2 compression is superior to the CCITT or Zip algorithms when compressing scanned monochromatic copy . JBIG2 (Joint Bilevel Image Experts Group) encodes compresses monochrome (1 bit per pixel) image data from 20:1 to 50:1 for pages full of text. Like other dictionary-based algorithms (LZW, ZIP) JBIG2 creates a table of unique symbols and when a subsequent symbol matches one in the table, it substitutes a token pointing to the table index. JBIG2 also compresses the entire table.
LZW compression is the compression of a file into a smaller file using a table-based lookup algorithm invented by Abraham Lempel, Jacob Ziv, and Terry Welch. Two commonly-used file formats in which LZV compression is used are the GIF image format served from Web sites and the TIFF image format. LZW compression is also suitable for compressing text files.
A particular LZW compression algorithm takes each input sequence of bits of a given length (for example, 12 bits) and creates an entry in a table (sometimes called a "dictionary" or "codebook") for that particular bit pattern, consisting of the pattern itself and a shorter code. As input is read, any pattern that has been read before results in the substitution of the shorter code, effectively compressing the total amount of input to something smaller. Unlike earlier approaches, known as LZ77 and LZ78, the LZW algorithm does include the look-up table of codes as part of the compressed file. The decoding program that uncompresses the file is able to build the table itself by using the algorithm as it processes the encoded input.
Flate method is based on the public-domain zlib/deflate compression method, which is a variable-length Lempel-Ziv adaptive compression method cascaded with adaptive Huffman coding. It is fully defined in Internet RFCs 1950,
ZLIB Compressed Data Format Specification , and 1951, DEFLATE Compressed Data Format Specification.Both LZW and Flate methods compress either binary data or ASCII text but (like all compression methods) always produce binary data, even if the original data was text. The LZW and Flate compression methods can discover and exploit many patterns in the input data, whether the data is text or images. Because of its cascaded adaptive Huffman coding, Flate-encoded output is usually much more compact than LZWencoded output for the same input. Flate and LZW decoding speeds are comparable, but Flate encoding is considerably slower than LZW encoding. Usually, both Flate and LZW encodings compress their input substantially. However, in the worst case (in which no pair of adjacent characters appears twice), Flate encoding expands its input by no more than 11 bytes or a factor of 1.003 (whichever is larger), plus the effects of algorithm tags added by PNG predictors. For LZW encoding, the best case (all zeros) provides a compression approaching 1365:1 for long files, but the worst-case expansion is at least a factor of 1.125, which can increase to nearly 1.5 in some implementations, plus the effects of PNG tags as with Flate encoding.
How to compress your PDF files
As we have introduced compression algorithms above, each compression method is suitable for certain color image. For example, using JPEG compression, color and grayscale images can be compressed by a factor of 10 or more. Effective compression of monochrome images depends on the compression filter used and the properties of the image, but reductions of 50% to 12.5% are common (or 5% to 2% for JBIG2 compression of an image of a page full of text). LZW or Flate compression of the content streams describing all other text and graphics in the document results in compression ratios of approximately 50%.
We can use image functions in Advanced PDF Tools software or pdfcompress command line tools of www.verypdf.com to compress your PDF files.
For example, on the Image panel of Advanced PDF Tools interface,
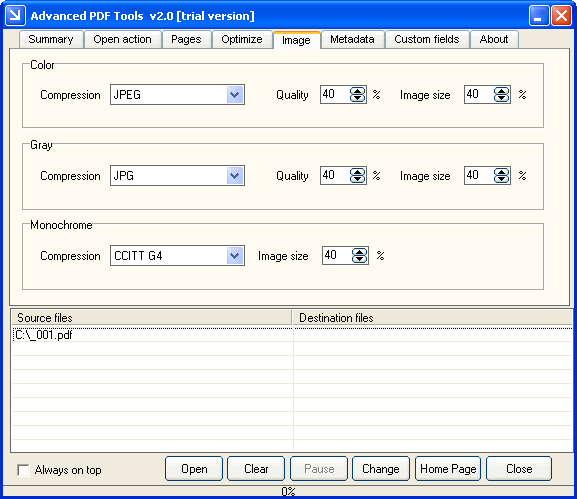
you can select the Compression, Quality,
Image size options for Color, Grayscale and
Monochrome images.
Image compression is where you actually reduce the data in the image by
lossless compression or by lossy compression, there are different algorithms
for performing this operation and we offer you the choice of all those
supported by Adobe Acrobat and PDF file, include Flate, JPEG, JPEG2000,
CCITT G4 etc. types.
In the pdfcompress command line tools, you can use the command
pdfcompress -i C:\input.pdf -o C:\output.pdf
and a configuration file "compress.ini" to compress your images, e.g.,
[colorimage]
compressformat=3
quality=40
imagesize=70
[grayimage]
compressformat=2
imagesize=70
[monimage]
compressformat=2
imagesize=70
For the details , please see pdfcompress command line user manual.
![]() Advanced
PDF Tools Command Line Home page.
Advanced
PDF Tools Command Line Home page.
Copyright © 2000-2006 by VeryPDF.com, Inc.
Send comments about this site to the
webmaster.