
Call PDF to Text OCR from Web or Windows Service
I downloaded the trial version of PDF2TXT yesterday and attempted to extract the text from the attached PDF. While I am aware that the trial version only extracts a limited number of actual pages per document, it seems that calling the cmd line interface from .NET is not working as far as extracting the text layer. When I use the GUI based version, it seems to work fine.
See attachments for source and output files.
Below is the code from the .NET text app. I’ve used the same process in the past with your Image2PDF OCR product and it works very well. All we are trying to do is to extract the text from the PDF so we can then index for full text search.
Is there anything in particular that we should be doing to get PDF2Text to generate via .NET? Any specific parameters that we MUST send to the cmd line?
I need to get successful runs from this right away, or move to another product. We’ve had good success in the past with your products and wish to continue using.
Thanks for your assistance!
inputPDFFilePath = @"C:\temp\indexRoot\test1.pdf";
outputTextFilePath = string.Format(@"C:\temp\indexRoot\test_{0}_.txt",DateTime.Now.Ticks.ToString());
// Start the child process.
Process p = new Process();
// Redirect the output stream of the child process.
p.StartInfo.CreateNoWindow = true;
p.StartInfo.UseShellExecute = false;
p.StartInfo.ErrorDialog = true;
p.StartInfo.RedirectStandardOutput = true;
p.StartInfo.RedirectStandardError = true;
p.StartInfo.RedirectStandardInput = true;
p.StartInfo.FileName = @"C:\source\visioncore\source\SLS\PDFTextExtraction\pdf2txt.exe";
//p.StartInfo.FileName = "pdf2txt.exe";
p.StartInfo.Arguments = string.Format("{0} {1} ", inputPDFFilePath, outputTextFilePath);
bool retval = p.Start();
return retval;
==================================
We recently purchased the PDF to Text OCR Converter Command Line product for use within a .NET Windows service. The PDF2Text works fine in a development environment, however, when the service is installed PDF2Text does not seem to run.
Both environments are running WinXP Pro. The non-dev environment is a VM. This same VM successfully runs you Image 2 PDF product.
A bit of background on the service implementation:
The service creates a FileSystemWatcher that listens to a directory that then calls the method below.
As the .Arguments go, I've tried with and without "-$" "XXXXXXXXXXXXXXXX".
private bool extractText( string inputPDFFilePath, string outputTextFilePath)
{
// Start the child process.
Process p = new Process();
// Redirect the output stream of the child process.
p.StartInfo.CreateNoWindow = true;
p.StartInfo.UseShellExecute = false;
p.StartInfo.ErrorDialog = true;
p.StartInfo.RedirectStandardOutput = true;
p.StartInfo.RedirectStandardError = true;
p.StartInfo.RedirectStandardInput = true;
p.StartInfo.FileName = @"C:\source\visioncore\source\SLS\PDFTextExtraction\pdf2txt.exe";
p.StartInfo.Arguments = string.Format("{0} {1} ", inputPDFFilePath, outputTextFilePath);
bool retval = p.Start();
}
I also tried running pdf2txt.exe using commandline on the VM environment and it works fine.
Any suggestions would be greatly appreciated.
==========================================
We suggest you may run your C# code inside Administrator user account instead of default system account to try again, can you get it work when you run it in Administrator user account?
VeryPDF
=========================================
We've tried running this under both an admin acct and a local system account, but it still doesn't work. What is odd is that I can see that pdf2txtocr.exe is running in Task Manager, but no text file is output UNTIL I stop the service. Then, the text file is written as originally expected.
Any ideas?
=========================================
We suggest you may use following example to run it from an interactive user account to try again.
Run conversion inside an interactive user account from service or web applications,
Please by following solution to run document conversion inside an interactive user account,
1. We assume pdf2txtocr.exe and PDF files are exist in C:\test folder.
Please add "Everyone" user account to "C:\test" folder and sub-folders, give "Full Control" permission to "Everyone" user account,
2. Download CmdAsUser.exe from following page,
http://www.verydoc.com/exeshell.html
You can also download it from following URL directly,
http://www.verydoc.com/download/cmdasuser.zip
3. Run following command line to test CmdAsUser.exe application,
C:\test\CmdAsUser.exe Administrator . /p password /c "C:\test\pdf2txtocr.exe" C:\test\in.pdf C:\test\out.txt
OR
C:\test\CmdAsUser.exe Administrator . /p password /c "C:\test\pdf2txtocr.exe" C:\test\in.pdf C:\test\out.txt
If you can run above command line in Command Line Window correctly, please call above command line from PHP by shell_exec() function or other web applications, then you will get it work properly.
Please notice:
1. You need modify "Administrator" and "password" parameters to correct user name and password in above command line, CmdAsUser.exe will launch doc2pdf.exe from this special user account with administrator privilege.
2. You may encounter Error 1314 in some Windows systems when you switch between user accounts, this is caused by permission setting, please by following steps to solve this 1314 Error,
ERROR 1314:
~~~~~~~~~~~~~
1314 A required privilege is not held by the client. ERROR_PRIVILEGE_NOT_HELD
~~~~~~~~~~~~~
To resolve this issue:
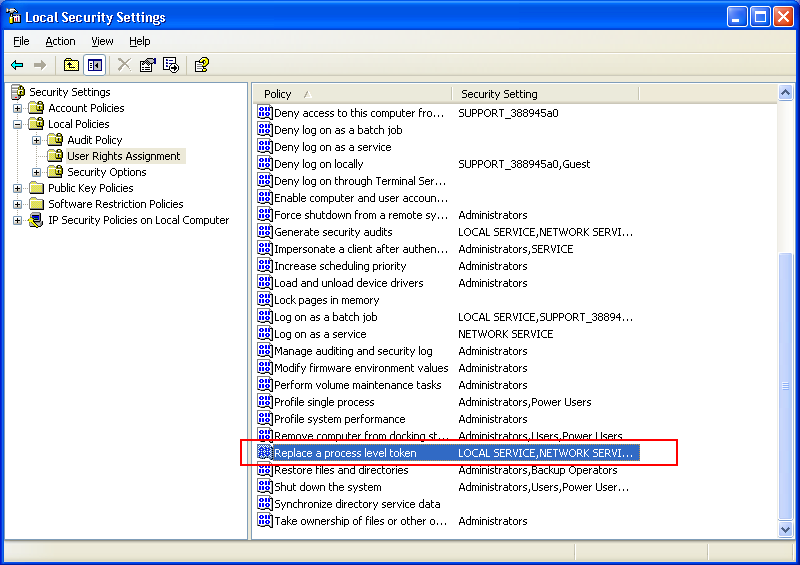
1. Click Start, click Run, type "secpol.msc", and then press ENTER.
2. Double-click "Local Policies".
3. Double-click "User Rights Assignment".
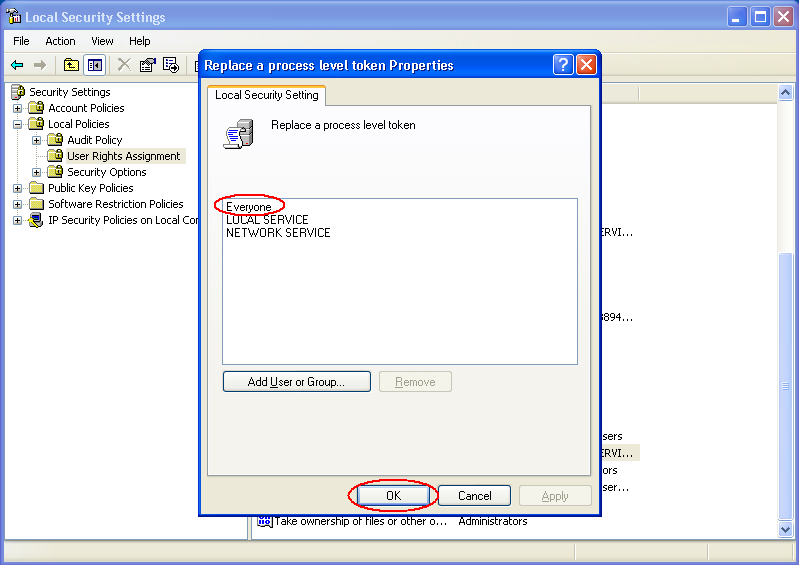
4. Double-click "Replace a process level token".
5. Click "Add", and then double-click the "Everyone" group 6. Click "OK".
7. You may have to logout or even reboot to have this change take effect.
Please refer to following two screenshots to understand above steps,
http://www.verydoc.com/images/err1314-1.png
http://www.verydoc.com/images/err1314-2.png
{kind=link}
{kind=link}
Please look at following page for the details about ERROR 1314,
http://www.verydoc.com/exeshell.html
If you still have same problem, please create a remote desktop account on your test machine, after we logged into your test machine, we will research this problem for you asap.
VeryPDF
==============================
Thanks, I'll give it a try.
Sent from my iPhone.
==============================
I have another question regarding the Img2PDF product. We currently use that in our application and have it running on a Win XP Pro VM.
Is there an updated version that will run on Windows Server 2003/2008?
We are currently set up with a SaaS implementation, however, we have client that will want a stand-alone version behind their firewall. It's not likely our clients will want to maintain a VM with an antiquated OS, so future purchases of the OCR tool we use would need to operate in a server OS environment.
===============================
Our Img2PDF product does support Windows Server 2003/2008 system, if you encounter any problem on Windows Server 2003/2008 system, please feel free to let us know, we will assist you asap.
VeryPDF
===============================